
/ Informatique
Projets
Surveillance de l'entrefer dans des turbines hydro-électriques compactes
traitement du signal, visualisation
2024-2025 (1 an)
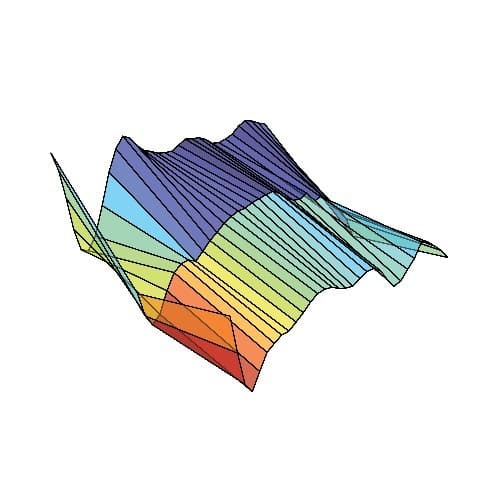
Déplié 3D de la valeur d'entrefer dans une turbine hydroélectrique.
La solution fournit des résultats rapides et interprétables par des experts, tout en réduisant le volume de données à stocker.
Analyse automatique de mise en page PDF et système RAG
analyse d'image, traitement automatique du langage naturel
2025 (4 mois)

Exemple de pdf analysé par l'outil développé dans ce projet.
J’ai ensuite développé un système de RAG permettant l’interrogation efficace de documents volumineux à partir de requêtes en langage naturel.
Détection automatique des phases d’éveil/sommeil en pédiatrie à partir d’enregistrements audio
traitement du signal, classification
2025 (3 mois)
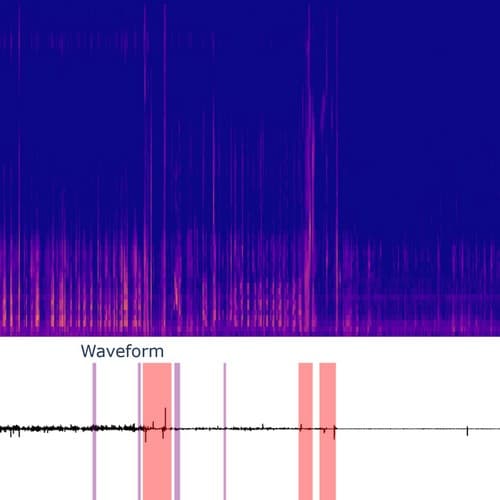
Spectrogramme de MEL avec annotations médicales.
J’ai entraîné des modèles conçus pour l'audio sur plus de 8000 heures d’audio, atteignant des performances comparables à l’état de l’art, et un fort potentiel de réduction des délais d’examen.
Analyse automatique de pièces d'usinage 3D
analyse d'image, classification, clustering
2024 (2 mois)
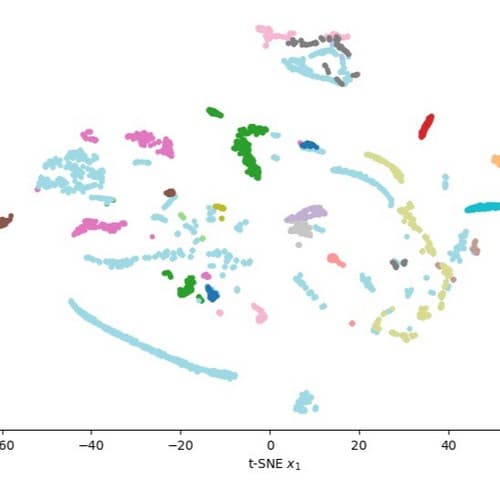
Projection TSNE des embeddings de pièces 3D.
Cette approche permet le regroupement automatique de pièces similaires ainsi que leur classification (vis, boulons, écrous).
Recherche avancée de profils scientifiques
traitement automatique du langage naturel, scrapping
2024 (3 mois)
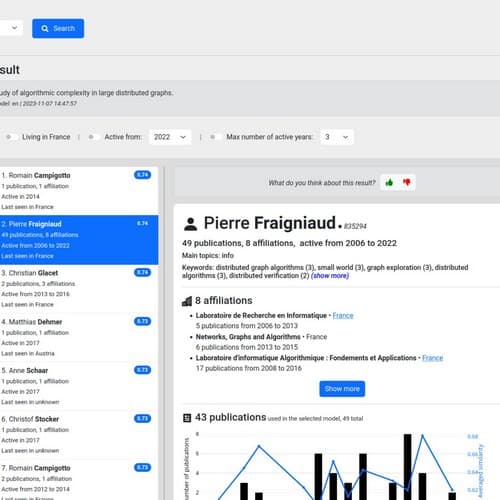
Résultat d'une requête sur l'outil développé.
L’outil repose sur des embeddings multilingues par auteur et permet la recherche en langage naturel, l’évaluation de la pertinence des publications et l’assistance à la lecture.
Recherche
Thèse
Connaissances du Domaine et Fonctions en Science des Données
Application à la Production d'Hydroélectricité
2020-23
Vasile-Marian Scuturici
Jean-Marc Petit
Amer-Yahia Sihem
Themis Palpanas
Marius Bozga
Frédérique Laforest
Pierre Senellart
Pierre Roumieu
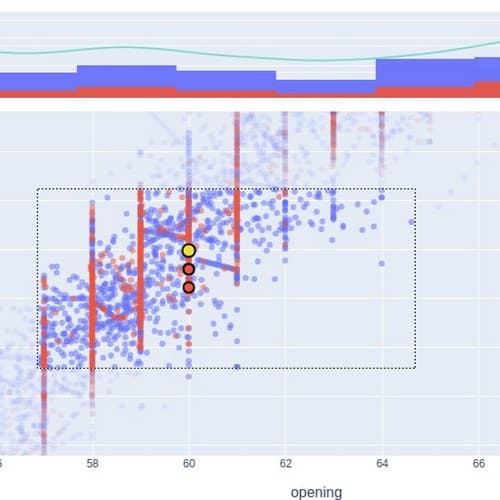
Scatter plot du graphe de contre-exemples d'un jeu de données issu d'une centrale hydro-électrique.
Thèse de master
Apprentissage Profond pour la Détection et l'Identification Automatique de Diatomées
pour le Diagnostic Écologique des Milieux d'Eau Douce
2020 (6 mois)
Cédric Pradalier
Ghassan AlRegib
Joseph Montoya
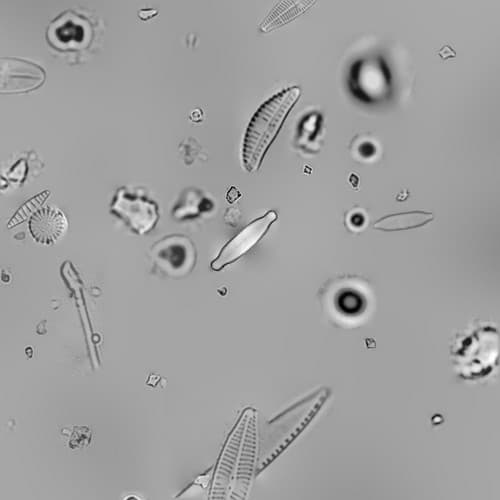
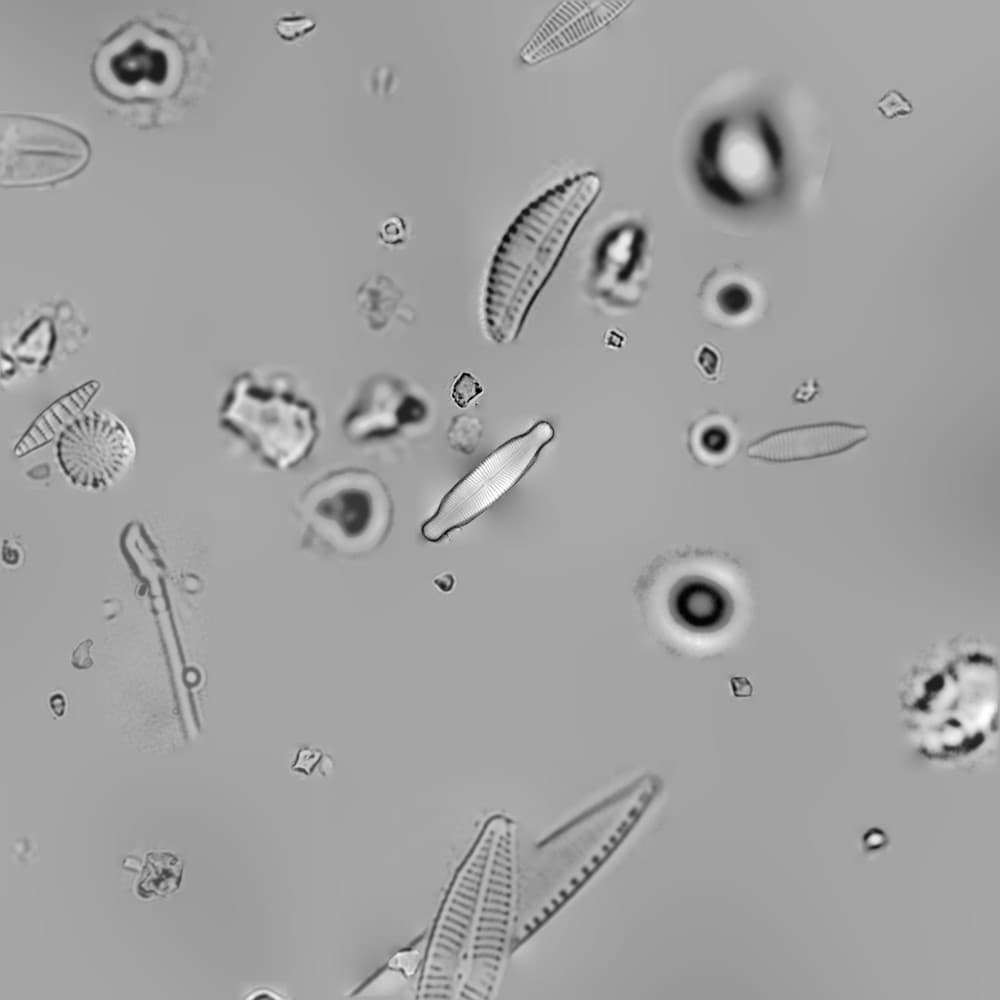
Exemple d'image de microscope synthétique générée dans cette étude.
Publications, séminaires...

/ Publications
Article de journal
Computing the g3-error with Relaxed Equality:
Complexity, Algorithms and Visualization
| Article de journal
Manuscrit de thèse
Domain Knowledge and Functions in Data Science,
Application to Hydroelectricity Production
| Manuscrit de thèse
Papier long
Functional dependencies with predicates: what makes the g3-error easy to compute?
| Papier long
Résumé étendu
Automatic Processing of Air Gap Monitoring Signals in Hydro-Generators
| Résumé étendu
Article de journal
Usefulness of synthetic datasets for diatom automatic detection using a deep-learning approach
| Article de journal
Papier long
Assessing the Existence of a Function in your Dataset with the g3 Indicator
| Papier long
Papier de démonstration
ADESIT: Visualize the Limits of your Data in a Machine Learning Process
| Papier de démonstration
Thèse de master
Deep-Learning for Automated Diatom Detection and Identification for the Ecological Diagnosis of Fresh-water Environments
| Thèse de master
/ Séminaires
Détection automatique des phases de réveil/sommeil en pédiatrie à partir d’enregistrements audio
Surveillance automatique de l'entrefer dans les hydro-générateurs compacts
Semaine des alternatives durables INSA Lyon (Lyon, France) • présentation orale • 2023
Global industrie (Lyon, France) • présentation orale • 2023
Évaluation de l'existence d'une fonction dans un jeu de données : complexité, algorithmique et visualisation
Graph and Databases Workshop [ANR GrR] (Lyon, France) • présentation orale • 2023
MaDICS Défis théoriques pour les sciences du climat (Paris, France) • poster • 2022
MaDICS Symposium [4e étition] (Lyon, France) • poster • 2022
MaDICS BigData4Astro (Lyon, France) • présentation orale • 2021
Utilité des jeux de données synthétiques pour la détection automatique de diatomées grâce à l'apprentissage profond
5ème colloque biennal des Zones Ateliers-CNRS (en ligne) • poster • 2020
/ Logiciels
/ Divers
Étudiant à l'école d'été Machine Learning for Oceans (ML4O)
Évaluateur pour SIGMOD et ICDM
Évaluateur pour ICDM